IJCNN 2026
BLOSSOM 
Block-wise Federated Learning Over Shared and Sparse Observed Modalities
- 1DaSH Lab, BITS Pilani K. K. Birla Goa Campus
- 2Queen Mary University of London
* Equal contribution

Abstract
Multimodal federated learning is essential for real-world applications such as autonomous systems and healthcare, where data is distributed across heterogeneous clients with varying and often missing modalities. However, most existing FL approaches assume uniform modality availability, limiting their applicability in practice. We introduce BLOSSOM, a task-agnostic framework for multimodal FL designed to operate under shared and sparsely observed modality conditions. BLOSSOM supports clients with arbitrary modality subsets and enables flexible sharing of model components. To address client and task heterogeneity, we propose a block-wise aggregation strategy that selectively aggregates shared components while keeping task-specific blocks private, enabling partial personalization. Our results show that block-wise personalization significantly improves performance, particularly in settings with severe modality sparsity. In modality-incomplete scenarios, BLOSSOM achieves an average performance gain of 18.7% over full-model aggregation, while in modality-exclusive settings the gain increases to 37.7%.
The Problem
Real-world multimodal clients rarely share the same sensors. Most federated learning methods assume every client observes every modality, or model only mild sample-level corruption. BLOSSOM instead targets structural modality missingness, where clients lack entire modalities. We organize this heterogeneity into three regimes of increasing difficulty:
Modality-complete
Every client observes all modalities. Reduces to a standard federated setup (e.g. FedAvg), our reference point.
Modality-incomplete
Some modalities are missing for subsets of clients, while others still hold the full set, creating a partial overlap across the federation.
Modality-exclusive
Clients hold entirely disjoint modality sets with no overlap, which is the hardest case, where naïve aggregation breaks down.
Method
BLOSSOM uses a late-fusion architecture split into three blocks: modality-specific encoders, a fusion module that integrates whichever modalities a client observes (missing ones are zeroed out before fusion), and a task head that produces the prediction. Rather than averaging the whole model as one unit, the server aggregates each block independently according to block type and modality availability, enabling partial personalization.
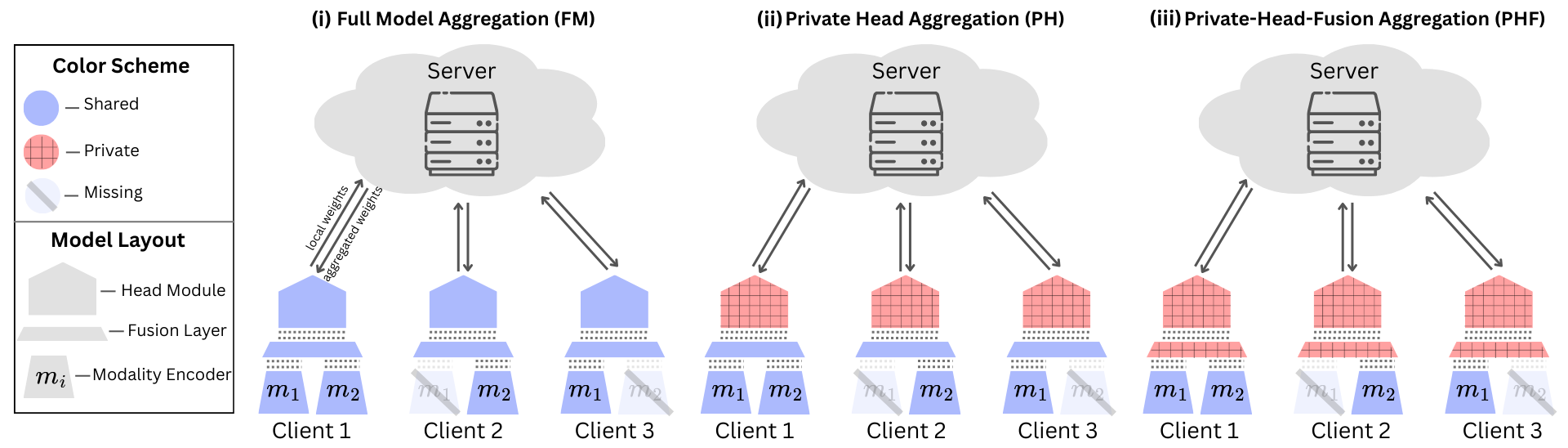
Three aggregation modes
FM
Full-Model Aggregation
Encoders, fusion, and head are all aggregated. Matches standard multimodal FL and serves as the primary baseline.
PH
Private Head
Encoders and fusion are shared, but each client keeps a private prediction head, adapting to local label distributions.
PHF
Private Head + Fusion
Only modality encoders are shared; both fusion and head stay private. Most robust under severe modality sparsity.
Each mode is evaluated with two fusion operators, ConcatFusion (concatenate embeddings, then project) and AttentionFusion (learned, modality-dependent weighting). The block-wise decomposition is optimizer-agnostic: it composes with FedAvg, FedAdam, or FedYogi without changing the architecture.
Experimental Setup
BLOSSOM is built on the Flower FL framework with
Hydra configuration management. All experiments use
10 clients, 60 communication rounds, and 1 local epoch per round. Non-IID label skew is
induced with a Dirichlet partition (α = 0.5). Missing modalities are denoted
a–b–c — meaning clients with modality 1
only, modality 2 only, and both — so 0–0–10
is 0% missing, 3–3–4 is 30%, and
5–5–0 is 50% (modality-exclusive).
| Task | Datasets | Modalities | Metric |
|---|---|---|---|
| Human Activity Recognition | KU-HAR, UCI-HAR | Accelerometer, Gyroscope | F1 |
| Healthcare | PTB-XL | ECG leads (I–aVF, V1–V6) | F1 |
| Multimedia | AV-MNIST | Image, Audio | Accuracy |
| Emotion Recognition | MELD, IEMOCAP | Audio, Text | Accuracy |
Results
Across all experiments, block-wise personalization gives an average gain of 19.8% over full-model aggregation, and the benefit grows precisely where the problem is hardest.
Modality-incomplete (30%)
+18.7%
avg. personalization gain over full-model aggregation
Modality-exclusive (50%)
+37.7%
gain in the most challenging, disjoint-modality setting
Sparsity drives the gain
Personalization gain rises from 18.7% at 30% missing to 37.7% at 50% missing, so the more modalities are absent, the more block-wise sharing helps.
Robust to label skew
Under non-IID label heterogeneity the average gain reaches 25.8%, versus 13.7% in the IID case, so personalization compounds across both kinds of heterogeneity.
Personalize the fusion too
PHF (private head + fusion) beats PH on average (18.8% vs 14.9%), and the gap widens with learned AttentionFusion, making PHF a robust default.
Biggest wins where no modality suffices
On modality-insufficient tasks, personalizing the fusion is critical, with average gains of 80% on KU-HAR and 73% on PTB-XL, where a single sensor stream cannot solve the task.
BLOSSOM also helps modality-incomplete clients contribute positively to the global model, and shows lower relative degradation than the state-of-the-art FedMultimodal benchmark under matched missing-modality rates, despite operating in the harder structural-missingness regime.
Citation
@inproceedings{mr2026blossom,
title = {BLOSSOM: Block-wise Federated Learning Over Shared and Sparse Observed Modalities},
author = {M R, Pranav and Chandwani, Jayant and Abdelmoniem, Ahmed M. and Paul, Arnab K.},
booktitle = {Proceedings of the International Joint Conference on Neural Networks (IJCNN)},
year = {2026},
url = {https://arxiv.org/abs/2603.27552}
}